

Python HTML Parsing benchmarks (using Arc90's Readability)
Oct 12, 2011If you're not familiar with the Readability project by Arc90, it is a bookmarklet that removes the clutter from web sites while you're surfing the web. When I say clutter I mean the ads, widgets, navigation elements etc. that often surround the main content of the website. Readability gives you a pristine view of the actual content.
Readability has been ported to many different languages including one in Python, which was written by Nirmal Patel (get the source here). Running readability server-side is useful if you're doing screen scraping and want to isolate the page content.
The actual algorithm is pretty simple, although I'm sure a lot of work has gone into testing and refining this algorithm to find out what works. In a nutshell, Readability traverses the DOM and uses a scoring function that rewards an element for containing text, punctuation, and class or id attributes typically associated with the main content of a site.
The python port by Nirmal Patel uses the BeautifulSoup html parsing library, which has a great interface, is pure-python, and just one file, so it's portable. The one thing that it lacks, though, is speed, which is why I re-implemented it using lxml, an html parser library for python that uses C modules to achieve ridiculous speeds. This was my first foray into lxml, and so far I'm impressed. It was extremely easy to program in.
Benchmarks
I did a quick and dirty benchmark by downloading the links on the first three pages of Hacker News and extracting the content. The results showed a larger than 7 fold increase in the mean speed for the lxml version!
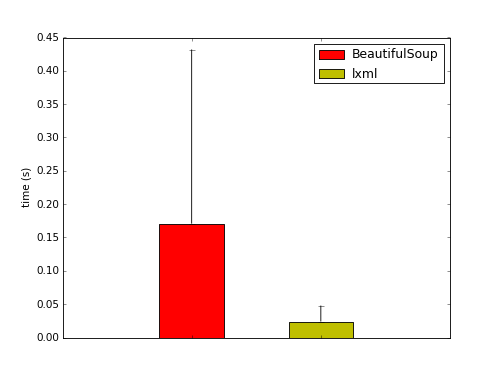
Here are the speeds for the last 24 results. In some cases it took close to two seconds to extract the content using the BeautifulSoup version.
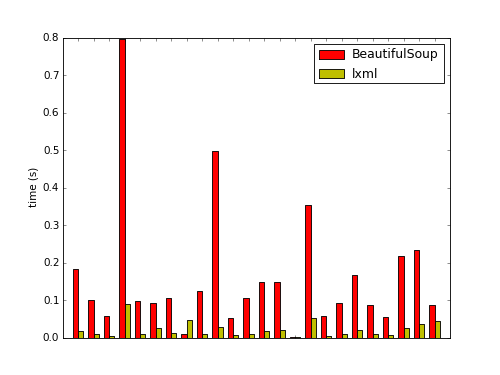
Not bad. A quick check of the xpaths (I used this code) to get the xpath for the BeautifulSoup version) of the results showed that isolated content did not differ at all between the two versions. If you have a project that needs to process web pages with any sort of high-throughput, then you might want to consider using my lxml port.
The benchmarking script I wrote can be found here.



